Muss man große Datenmengen verarbeiten, die möglicherweise sogar in vielen unterschiedlichen Datenformaten vorliegen und aus unterschiedlichen Quellen stammen, kommt man um den Einsatz von Message-Brokern nicht mehr herum. Diese sorgen für die effiziente Übermittlung von Daten vom Sender zum Empfänger, ohne dass zwischen Sender und Empfänger jeweils eine eigene Schnittstelle programmiert werden muss. Bei ONTEC beschäftigen wir Experten, die sich seit vielen Jahren mit diesen Systemen im Allgemeinen und mit Apache Kafka im Besonderen auseinandersetzen.
Apache Kafka im Überblick – Was ist Apache Kafka?
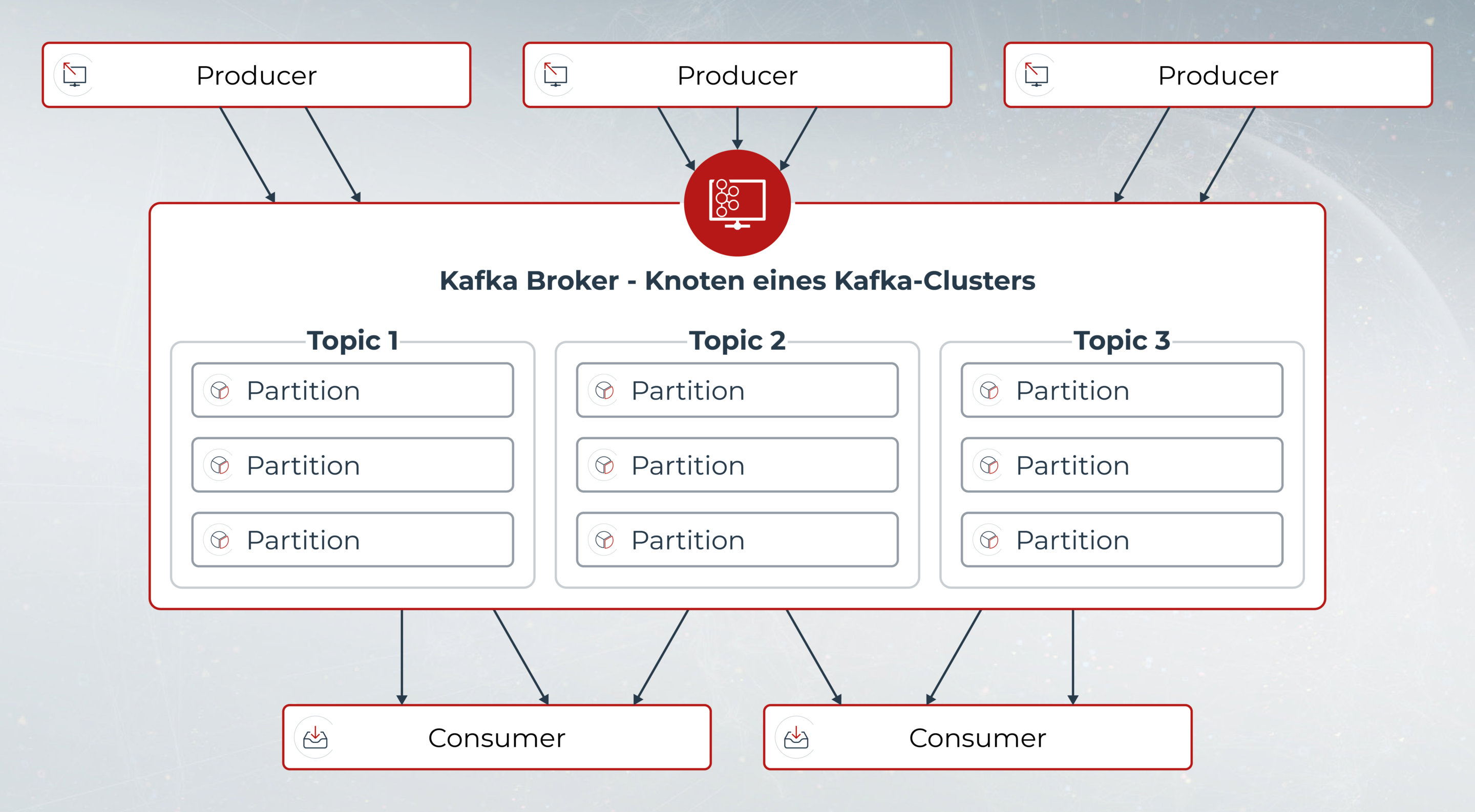
Apache Kafka ist ein komplexer Message-Queueing-Dienst zur Verarbeitung großer Datenströme und eines der aktivsten Projekte der Apache Software Foundation. Der Message-Broker ist eine Open-Source-Anwendung und wurde ursprünglich 2011 als Inhouse-Projekt bei LinkedIn entwickelt. Seit der Veröffentlichung unter freier Lizenz (Apache 2.0) wurde Kafka zu einer leistungsfähigen Open-Source-Plattform ausgebaut, die heute unter anderem bei Airbnb, Zalando, Netflix, Twitter oder Microsoft eingesetzt wird.
Apache Kafka vs. traditionelle Message Queues
In traditionellen Message-Queues wie RabbitMQ oder ActiveMQ landen alle eingehenden Daten in einer Warteschlange und werden nach erfolgreicher Verarbeitung wieder aus dieser entfernt. Im Gegensatz dazu arbeitet Apache Kafka nach dem Publish/Subscribe-Modell, das den simultanen Datenabruf mehrere Subscriber gleichzeitig und unabhängig von den Publishern ermöglicht.
Die Daten verbleiben dabei im System und können jederzeit wiederverwendet werden. Das erlaubt ein Reprocessing, wenn sich beispielsweise der Erkenntnisstand ändert und Daten anders oder in einem anderen Zusammenhang verwendet werden sollen als in der Vergangenheit.
Vorteile beim Einsatz von Apache Kafka
Dank Datenpartitionierung, einer flexiblen Architektur und hoher Skalierbarkeit ist das System ausfallsicher und kann auch sehr große Datenmengen in Echtzeit verarbeiten, indem zusätzliche Cluster einfach bei Bedarf dazugeschaltet werden.
Trotz seiner hohen Leistung ist Apache Kafka ressourcenschonend, da nicht mehr jeder Datenverwender (Consumer) mit jedem Datenersteller (Producer, Publisher) einzeln kommunizieren muss, sondern alles über den Message Broker abgewickelt wird.
Sie haben Fragen zu Apache Kafka, seinen Funktionen oder wie Sie ihn konfigurieren? Wir beantworten Ihnen diese gerne! Rufen Sie uns an, Sie werden es nicht bereuen.
Der primäre Anwendungsfall bei der Entwicklung von Apache Kafka war das Activity Tracking der Webpräsenz von LinkedIn. Das System eignet sich somit für Problemstellungen, bei denen viele Daten aus unterschiedlichen Quellen verarbeitet werden müssen und für die eine rasche Verarbeitung in Echtzeit erforderlich ist.
Apache Kafka stellt zu diesem Zweck verschiedene Schnittstellen zur Verfügung, um die Daten in Kafka-Cluster zu schreiben und das flüssige Speichern und Verarbeiten auch von umfangreichen Datenströmen diverser Quellen zu ermöglichen. Die Kafka Connect API, die auf der Producer- und Consumer-API basiert, dient dabei als Schnittstelle für den Datenaustausch.
Kafka als traditioneller Nachrichtenbroker
Nachrichtenbroker werden aus einer Vielzahl von Gründen verwendet (z.B. um die Datenverarbeitung von den Datenproduzenten zu entkoppeln, um nicht verarbeitete Daten zu puffern, …) Im Vergleich zu den meisten Messaging-Systemen hat Kafka einen höheren Datendurchsatz, eine integrierte Partitionierung, eine höhere Fehlertoleranz und repliziert Daten besser. Das macht ihn zu einem guten Ersatz für traditionelle Nachrichtenbroker und zur besten Lösung für große Nachrichtenverarbeitungsanwendungen.
Website-Aktivitäsverfolgung
Bei der Website-Aktivitätsverfolgung mit Kafka werden Seitenaufrufe, Suchvorgänge oder andere Aktionen, die Benutzer ausführen können, in zentralen Themen mit einem Thema pro Aktivitätstyp (Feeds) veröffentlicht. Diese Feeds können für eine Reihe von Anwendungsfällen abonniert werden, einschließlich Echtzeitverarbeitung, Echtzeitüberwachung und Laden in Hadoop- oder Offline-Data-Warehousing-Systeme für Offline-Verarbeitung und -Berichterstellung. Die Website-Aktivitätsverfolgung kann sehr umfangreich sein und ist der klassische Anwendungsfall für Apache Kafka.
Metrikenerstellung
Kafka lässt sich gut für die Überwachung und Analyse von Betriebsdaten einsetzen, insbesondere in verteilten Umgebungen und bei großen Datenmengen. Dabei werden aus allen Anwendungen Statistiken aggregiert und in zentralen Feeds dargestellt.
Event Sourcing
Event Sourcing ist ein Stil des Anwendungsdesigns, bei dem anstatt reiner Zustände, ausgeführte Events als zeitlich geordnete Folge von Datensätzen gespeichert und protokolliert werden. Der eigentliche Status wird aufgrund der generierten Events reproduziert in nicht direkt in einer Datenbank gelesen. Das hat den großen Vorteil, dass alle Änderungen jederzeit nachvollziehbar sind, auch rückwirkend für spätere Analysen. Die Möglichkeit Kafka auf mehrere Server zu verteilen und als Cluster einzusetzen, hält seine Performance immer gleich hoch, obwohl beim Event Sourcing mehrere 100 Millionen von Daten gespeichert werden. Durch Replizierung aller Eventdaten auf mehrere Partitionen sind diese gut gesichert. Außerdem können Schreib- und Lesezugriffe effizient aufgeteilt werden.
Stream Processing
Durch die dauerhafte Speicherung von Eventströmen ist Kafka besonders gut für Stream Processing geeignet. Die Daten können dabei in mehrstufigen Verarbeitungspipelines verwendet werden. So werden beispielsweise zunächst rohe Eingabedaten von Kafka-Themen konsumiert und dann aggregiert, angereichert oder anderweitig in neue Themen für den weiteren Konsum oder die Weiterverarbeitung umgewandelt. Eine Verarbeitungspipeline für die Empfehlung von Nachrichtenartikeln könnte etwa Inhalte aus RSS-Feeds von Drittsystemen crawlen und sie als Artikel veröffentlichen. In einem weiteren Verarbeitungsschritt könnte der Inhalt normalisiert oder dedupliziert und der bereinigte Artikel in einem neuen Thema veröffentlicht werden. Eine abschließende Verarbeitungsstufe könnte diesen Inhalt Benutzern empfehlen und als Echtzeit-Streaming anbieten. Dafür stellt Apache Kafka mit Kafka Streams eine einheitliche Streaming-Plattform mit einer Stream-Verarbeitung in Java bereit, die sich mit externen Stream-Verarbeitungen wie etwa Amazon Web Services (AWS), Google Cloud Platform (GCP) oder Microsoft Azure verbinden lässt und durch einen hohen Durchsatz und eine geringe Latenz für die Verarbeitung von Echtzeit-Datenfeeds auszeichnet. Die Apache Kafka Streams-API ist eine schlanke, aber dennoch leistungsstarke Java-Bibliothek, die eine fließende und störungsfreie Verarbeitung sicherstellt. Das Aggregieren von Daten, die Erstellung von Windowing-Parametern und Zusammenfassen von Daten innerhalb eines Streams sind nur einige beispielgebende Anwendungsmöglichkeiten.
Anmeldeprotokoll
Durch seine Protokollkompaktierungsfunktion unterstützt Kafka die Wiederherstellung von Daten, indem er bei deren Replikation zwischen Knoten hilft und als Neusynchronisierungsmechanismus für ausgefallene Knoten dient. Damit kann er als externes Commit-Log für ein verteiltes System eingesetzt werden.
Das ONTEC-Leistungsportfolio für Apache Kafka
Betrieb
Egal, ob in Ihrer bestehenden Infrastruktur oder in der Public Cloud, wir betreiben Apache Kafka in der Umgebung Ihrer Wahl.
Consulting
Sie fragen sich, wie Sie Apache Kafka optimal bei Ihnen im Unternehmen einsetzen können? Wir beraten Sie gerne hinsichtlich Architektur, Funktionsweise und optimaler Implementierung.
Fehleranalyse
Apache Kafka arbeitet nicht, wie gewünscht und Sie können das Problem nicht finden? Unsere Experten stehen Ihnen mit Rat und Tat zur Seite.
Hosting
Um einen leistungsstarken Kafka-Cluster zu betreiben, brauchen Sie die richtige Infrastruktur. Gerne stellen wir Ihnen diese zur Verfügung.
KONTAKT AUFNEHMEN
Hannes Gruber ONTEC AG
Kundenorientierung bedeutet für mich sich in die Lage des Kunden versetzen zu können. Genaues Zuhören, verstehen und ein fachlich top aufgestelltes Team sind hierbei entscheidend, um den Kunden die optimale Lösung anzubieten.